- Product

- Pricing
- Affiliate Program
- Developers
- Resource
 EN
EN
As data becomes the core of modern business and research, web scraping has become a key technology for acquiring important online data. However, with websites adopting stricter anti-scraping strategies against automation tools, traditional scraping techniques face increasing challenges. In this context, anti detection browsers have emerged as a new option for scraper developers.
While web scraping is powerful, it encounters various challenges in practice:
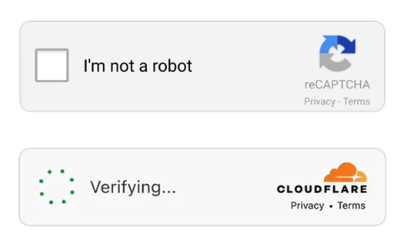
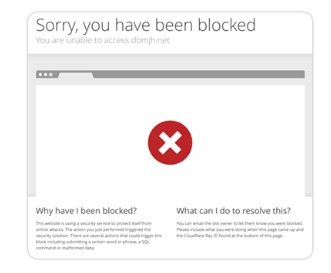
Anti-Scraping Systems: Many websites deploy complex anti-scraping systems, such as Cloudflare and CAPTCHA verification.
Dynamic Content Handling: Dynamic content refers to content that changes based on user input or other factors (such as the time of day or location). This can make it difficult to collect accurate data, as scraping tools may not know what content to look for or where to find it. To overcome this challenge, it is important to carefully consider the structure of the target website and use tools like regular expressions to identify and extract specific data.
Behavior Detected as Abnormal: Websites may detect abnormal user behavior. If requests are too frequent or if certain trap links are entered, it may lead to account or IP bans.
MoreLogin's anti-detection browser offers an effective solution with the following advantages:
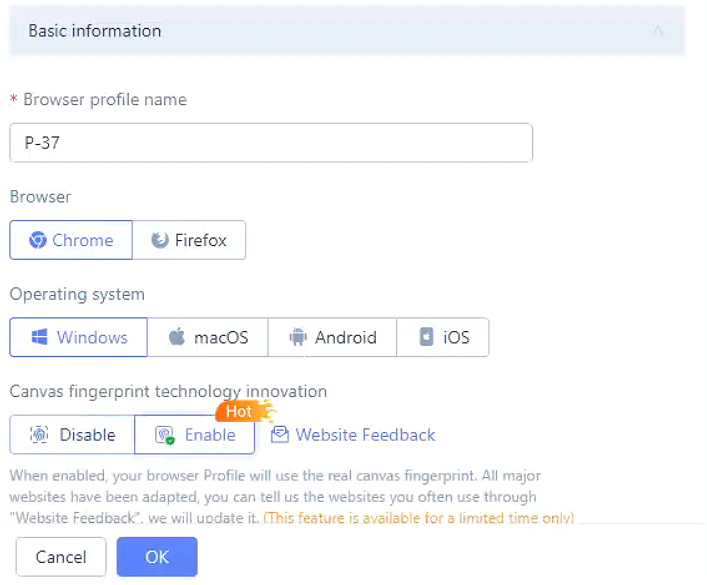
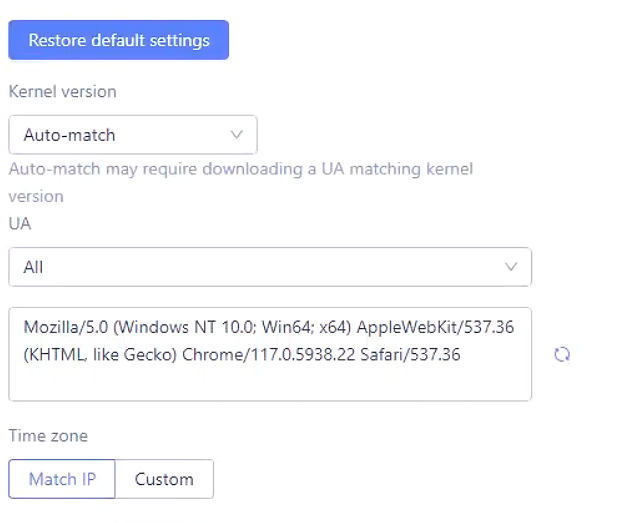
Professional core fingerprint team providing high-fidelity environment fingerprints: It can change user browser fingerprints, screen resolutions, fonts, WebRTC, etc., making it appear as though different users are accessing the website. Additionally, by binding an IP in MoreLogin, you can obscure your real location, making it difficult for the scraper to be detected. This allows you to easily bypass restrictions on more challenging websites.
Privacy Protection: It offers enhanced privacy protection features, such as disabling Canvas and WebGL tracking, reducing the risk of personal information leakage.
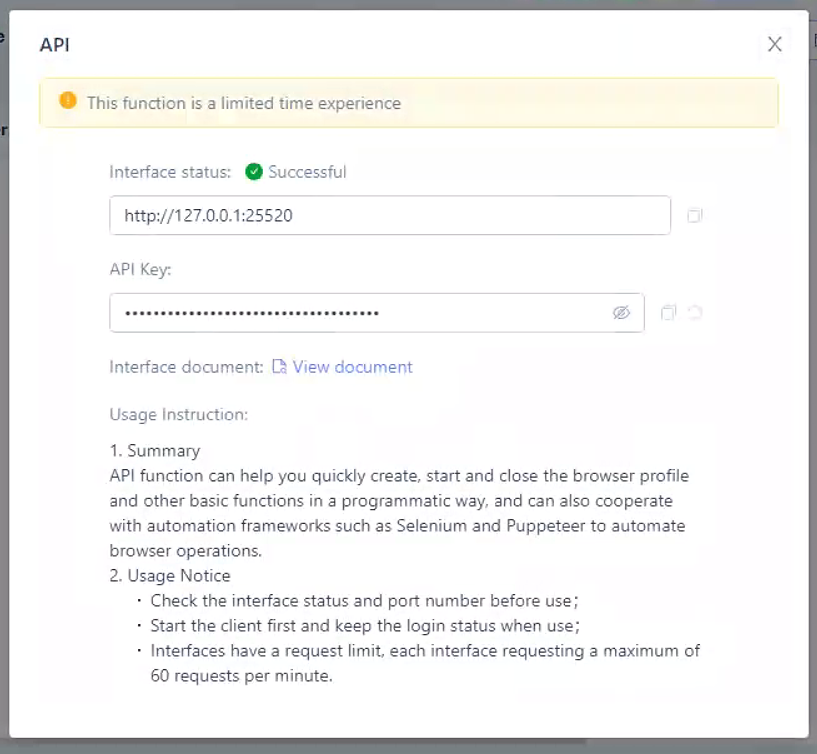
Automated Tasks: MoreLogin supports built-in API automation. Through the API, you can create real canvas fingerprints, and the fingerprint feature configuration for each browser is customizable. By opening ports, you can use common automation frameworks like Playwright, Selenium, Puppeteer, and Cypress. Furthermore, you can add proxies for each browser through the API, simplifying your scraping workflow.
Improve efficiency: pass
1. Download and install the MoreLogin fingerprint browser: https://www.morelogin.com/download/
2. After installation, you will see the API option on the homepage.
3. Connect to MoreLogin via API for automation. For API documentation, please refer to our help center: https://docs.morelogin.com/l/en/api-2-0-0
EN